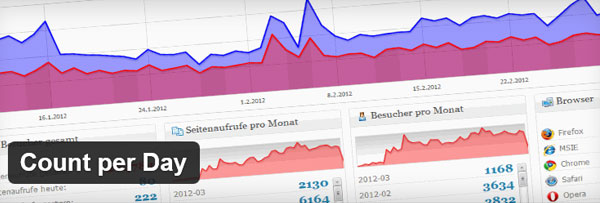
統計を表示する「 Count per Day 」は非常に便利なプラグインです。「閲覧数」「訪問数」「閲覧ページ回数」「リアルタイム」表示など Google アナティリクスよりも見やすくなっています。まさに一目でアクセスログ(統計の推移)がわかる優れものですね。
SEOの向上にも非常に役に立ちます。プラグインをインストールした当初はわずかな人数だったのだが、日々順調に「訪問者数」「閲覧数」ともに伸ばしていました。
が…先日ふとあることが頭をよぎる。「なんか順調に推移しててるけど、これ、どのくらい正確なんだろう??」と思い始めた。「 Count per Day 」の表示を見てみると、訪問国がおかしなことになっているのに気が付きました。
まぁ日本からの訪問者は当然だが、「アメリカ」「ウクライナ」「中国」が圧倒的に多いじゃないか…。どーゆーこと??「ウクライナ」とか…国の名前をかろうじて知っている程度である。まさかこのWordPressをハッキングしようとしているのか…。
狙われてる?!いや、そんなはずは…、などど、ありもしない被害者妄想全開で恐怖に震えていたのであった。
とゆーわけで、Google様で調べてみることにしました。
巡回ロボット(クローラー)が原因?!
クローラーとは、各検索サイトや研究機関がWebサイトの情報を収集するために利用している自動巡回ロボットのことです。
クローラーはHTMLに記載されているリンクを一気にたどって行くため、人間のユーザーとは明らかに異なるアクセスを行います。検索サイトでの検索順位を上げるためには、クローラーがWebサイトを訪れることは歓迎すべきことです。
しかし、ユーザーの動きを知るために行うアクセスログ解析にとっては不要なデータとなってしまいます。
従ってアクセスログ解析を行うにあたっては、可能な限りクローラーの残したログデータを排除して分析を行います。クローラーの多くはアクセスログのデータ中にあるユーザーエージェントの情報にクローラーであることを明示しています。
そのクローラーに関する情報を掲載したWebサイトのURLを記載しているので、データの判別と排除が可能です。しかし、中にはクローラーであることを明示せず、一般のユーザーを偽装するようなものもあります。
完全に排除するためには怪しいアクセスをひとつひとつ検証していく必要があります。
参照引用:MITSUE-LINKS
クローラーの説明によれば、「アクセス解析にとってクローラーは不要」とのこと。さっそくプラグインの設定でクローラーを除外してみました。
除外クローラー一覧
詳細が不明なクローラーもいくつかあります。下記のクローラーは基本的に「トラフィックを増大させる」「サイトの動作を重くする」等の理由から拒否したほうが良いでしょう。
もちろん拒否しなくてもサイトの運営には問題ありません。できるだけ正確なアクセスログ解析をしたいのであれば、クローラーを除外することで精度はより向上すると思われます。
デフォルトで設定されているクローラー
| search | クローラーの別称 |
|---|---|
| crawler | クローラーの別称 |
| ask.com | アメリカのyahoo知恵袋的なサイトのクローラー |
| validator | サイトの文法検証クローラー |
| snoopy | HTTP クライアントライブラリのクローラー |
| suchen.de | mozilla fir fox のアドオン クローラー |
| suchbaer.de | 詳細不明 |
| shelob | Mattworkというサイトに行きついたが… 詳細不明 |
| semager | mozilla関連のクローラー |
| xenu | サイトクローラー |
| such_de | 詳細不明 |
| ia_archiver | キャッシュを主に行うクローラー |
| Microsoft URL Control | アクセス解析会社のクローラー(Microsoftとは関係なし) |
| netluchs | ドイツの会社のクローラー 詳細不明 |
ここから追加クローラー |
|
| ichiro | NTTレゾナント株式会社が運用しているWebクローラー |
| findlinks | ドイツの会社のクローラー 詳細不明 |
| gooblog | gooブログ検索のクローラー |
| UnwindFetchor | Twitter関連のクローラー |
| PostRank | Google関連のクローラー |
| Crowsnest | Twitterのタイムライン関連のクローラー |
| larbin | xmlを構築するためのものらしい フリーで公開されているクローラー |
| JS-Kit | Twitter関連のクローラー |
| twieve | TwitterからEvernoteにつぶやきなどを自動的に送り込むクローラー |
| Hatena::BookmarkAcoon | はてぶのクローラー |
| Jakarta Commons | Apacheのライブラリ関連のクローラー |
| MetaURI API | URL短縮サービスのクローラー?? 詳細不明 |
| WWW-Mechanize | Rubyに関するライブラリクローラー |
| facebookexternalhit | facebookのクローラー |
| butterfly | Twitter関連の海外クローラー |
| FlipboardProxy | Firefox関連のクローラーらしい 詳細不明 |
| Googlebot-Image | 画像情報を取得するクローラー |
| Yahoo-MMCrawler | 画像情報を取得するクローラー |
| Baiduspider | 画像情報を取得するクローラー |
| BaiduImagespider | 画像情報を取得するクローラー |
| e-SocietyRobot | 早稲田大学のクローラー |
| Yeti | NAVER(韓国)のクローラー |
| Googlebot | Googleが採用しているクローラー |
| ICC-Crawler | NICTユニバーサルコミュニケーション研究所のクローラー |
| Steeler,e-SocietyRobot | 大学(東大、早大)のクローラー |
| Teoma | ask.comと何やら関係がありそうなクローラー |
| Baiduspider | 中国のクローラー |
| YodaoBot | 中国のクローラー |
| TurnitinBot | アメリカのエデュケーション(学生向け)クローラー |
| BecomeJPBot | ショッピングサーチ関連のクローラー |
| BecomeBot | ショッピングサーチ関連のクローラー |
参照・一部引用サイト:Mermaid::Tavern 様
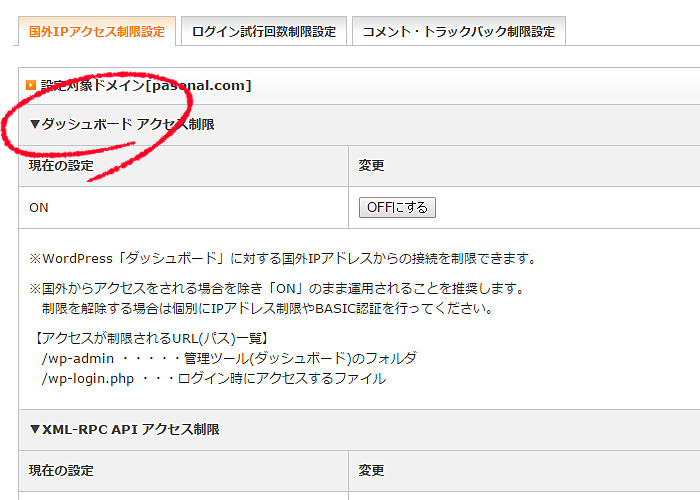
国外IPを拒否
さて、上記のクローラーを設定できたら、次はXサーバーから国外IPを拒否する設定を行いましょう。弊社のサイトはすべて日本語であり、多言語には対応していません。
また、セキュリティ的にも効果を高めることができます。
Xサーバーのセキュリティ設定
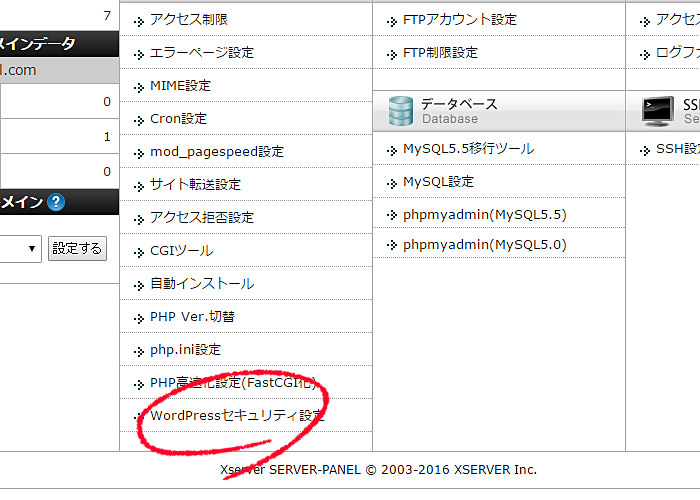
国外IPを拒否に設定
上記以外にもhtaccessから国外IPを拒否することもできますが、あまりおすすめ出来ません。気になるならネットで調べてみましょう!