さて、皆さんはこんな経験ありませんか?
- 「Excelで顧客データや売上データを管理しているけど、もう限界・・・」
- 「Excelでシートが増えすぎて、ごちゃごちゃ・・・」
- 「Excelで関数を使いすぎて、更新が遅いんだけど・・・」
Excelは大変便利ですが、データ容量が増えてくると困ることがたくさん増えてきます。そんな時はデータベースを使用して、一段階上のデータ管理を目指しましょう!
今回は<データベースの正規化>を分かりやすく解説したいと思います。
関連講座
- Access データベースの正規化 講座 Vol.1 ← ココ
- Access データ型の決定とフィールドの構築 講座 Vol.2
- Access ルックアップウィザード 講座 Vol.3
- Access リレーションシップ 講座 Vol.4
- Access クエリ作成 講座 Vol.5
- Access 関数の使い方 講座 Vol.6
実用書のご紹介

データベースを業務で使用する機会は多々あるでしょう。Accessの操作などは、書店においてある本で十分理解できます。
でもネックになるのは、データベースの設計なのです。こればっかりは専門書を購入して勉強しないと、なかなか理解は深まりません。今回は私が愛用している「達人に学ぶDB設計 徹底指南書 初級者で終わりたくないあなたへ」をご紹介します。この本はやり方だけではなく、正規化におけるタブーなどの詳細な情報が記載されていることです。
「何故そうしなければならないのか?」「どうしてダメなのか?」が詳細に載っているので、非常に勉強になります。Amazonでの評価も総じて高いのもうなずけます。
本気で学ぶのであれば、是非一度読んでおくべきです。

ポイント
細かい点は色々ありますが、データベースを作成する上での重要ポイントは下記の3つになります。
- <ルールの明文化>
- <データ項目の洗い出し>
- <データベースの正規化>
1.ルールの明文化
データ項目を洗い出す前準備としてあらかじめ決めたルールを明文化しておきます。
例えば・・・
注文の情報について
- 注文IDは、「5桁のゼロ詰め」とする。
- 1度の注文には、必ず1人の担当者が割り振られる。
- 注文は「いつ・だれが・何を・いくつ購入し・その時担当した授業員が誰なのか」を知りたい。
- 顧客は、複数の商品をまとめて購入することができる。
顧客の情報について
- 従業員IDの頭文字は、「CS + 3桁」とする。
- 顧客の情報は<氏名><住所><連絡先>が必ず必要である。
従業員の情報について
- 従業員IDの頭文字は、「J + 3桁」とする。
- 従業員の情報は<氏名><住所><年齢><連絡先><役職>が必ず必要である。
- 会社には複数の従業員がおり、役職(例:社員、パート、アルバイト)ごとに分かれている。
商品の情報について
- 商品は区分(例:多年草、球根類、水生植物、ハーブ、樹木類)ごとに分かれている
- 商品区分の頭文字は命名ルールに従い設定する(例:多年草 → T1、球根類 → K1、樹木類 → J1)
どうでしょうか?
このように命名ルールや規則を設定することで、格段に<データ項目の洗い出し>が楽になります。
2.データの項目の洗い出し
まず必要になるのが<データ項目の洗い出し>です。これは業務により項目が変わるので一概には言えません。ここでは、例えば<顧客を管理したい>という名目でデータ項目を洗い出してみることにします。
顧客を管理するためにパッと思いつく必要な項目は以下のような感じです。
顧客管理
- <氏名>
- <ふりがな>
- <住所>
- <連絡先>
商品を管理したいとなると、パッと思いつく必要な項目は以下のような感じです。
商品管理
- <商品名>
- <単価>
- <商品区分>
仕入先を管理したいとなると、パッと思いつく必要な項目は以下のような感じです。
仕入れ管理
- <仕入先名>
- <代表者名>
- <住所>
- <連絡先>
- <担当者名>
どうでしょう?
だいたいイメージできましたか?業務経験がある人だと、データを管理するために必要な項目がある程度分かってくると思います。
※本来はもっと複雑な項目になりますが、ここでは敢えて解説しやすい項目にしています。
テーブルの正規化
正規化の手順は第一~第三正規形まで行います。本来は第三正規形以上あります。しかし、第三正規形まで行えば、データの整合性を保つことができるため、今回は第三正規形まででストップさせます。
元テーブル
| 注文日 | 顧客名 | 住所 | 連絡先 | 商品名 | 単価 | 区分コード | 区分名 | 個数 | 金額 |
|---|---|---|---|---|---|---|---|---|---|
| 2015/10/01 | 山田 | xxx | xxx | コケ | ¥500 | S1 | 水生植物 | 1 | ¥500 |
| スミレ | ¥1,000 | T1 | 多年草 | 1 | ¥1,000 | ||||
| 2015/10/25 | 佐藤 | xxx | xxx | 苗木 | ¥1,500 | J1 | 樹木類 | 1 | ¥1,500 |
| 2015/11/14 | 武田 | xxx | xxx | タンポポ | ¥800 | T1 | 多年草 | 2 | ¥1,600 |
まずは、お客さんが商品を購入した時に必要であろう項目を羅列します。上記の表では、「いつ」「誰が」「何を」「いくつ」買い、「どれだけの金額だったのか」が一目で分かります。
この元テーブルを分離して、テーブルを正規化していきます。
第一正規化
| 注文日 | 顧客名 | 住所 | 連絡先 | 商品名 | 単価 | 区分コード | 区分名 | 個数 | 金額 |
|---|---|---|---|---|---|---|---|---|---|
| 2015/10/01 | 山田 | xxx | xxx | コケ | ¥500 | S1 | 水生植物 | 1 | ¥500 |
| 2015/10/01 | 山田 | xxx | xxx | スミレ | ¥1,000 | T1 | 多年草 | 1 | ¥1,000 |
| 2015/10/25 | 佐藤 | xxx | xxx | 苗木 | ¥1,500 | J1 | 樹木類 | 1 | ¥1,500 |
| 2015/11/14 | 武田 | xxx | xxx | タンポポ | ¥800 | T1 | 多年草 | 2 | ¥1,600 |
第一正規化で行うことは次の3つです。<スカラ値の原則><重複項目の解消><導出項目の排除>。スカラ値の原則とは「一つのセルには一つの値のみ」を格納することです。上記の元テーブルはスカラ値の原則を満たしている状態になります。これが一つのセルに複数の項目が格納されている状態だとNGになります。
次に、重複項目を解消していきます。
元テーブルの「2015/10/01」の「山田さん」の例を見てください。同じ人物が異なる商品を購入したため、セルが結合されている状態になっています。
これを解消すると、上記のような表となります。
導出項目の排除後
| 注文日 | 顧客名 | 住所 | 連絡先 | 商品名 | 単価 | 区分コード | 区分名 | 個数 |
|---|---|---|---|---|---|---|---|---|
| 2015/10/01 | 山田 | xxx | xxx | コケ | ¥500 | S1 | 水生植物 | 1 |
| 2015/10/01 | 山田 | xxx | xxx | スミレ | ¥1,000 | T1 | 多年草 | 1 |
| 2015/10/25 | 佐藤 | xxx | xxx | 苗木 | ¥1,500 | J1 | 樹木類 | 1 |
| 2015/11/14 | 武田 | xxx | xxx | タンポポ | ¥800 | T1 | 多年草 | 2 |
次に、導出項目を排除していきます。
導出項目とは、「金額」のことです。金額は<単価>×<個数>で計算できる項目なので、第一正規化の段階で排除します。排除すると下記のような表となります。どうでしょう?かなりスッキリしましたね!
これで第一正規形が完了しました。
第二正規化
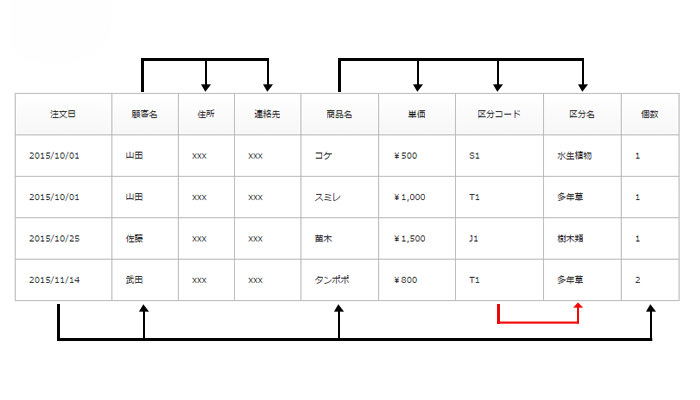
第二正規化で行うことは以下の通りです。
<部分従属関数>の分離。
<部分従属関数>とは<属性の塊>のことだと思ってください。
それぞれの関係性を線で表すと下記のような感じになります。
- 顧客関連の情報は<顧客名><住所><連絡先>です。
- 商品関連の情報は<商品名><単価><区分コード><区分名>
- 注文関連の情報は<注文日><顧客名><商品><個数>です。
注文関連の情報はイメージしにくいかもしれません。
<いつ><誰が><何を><いくつ買ったか>を考えると分かりやすくなります。上記の関係性に従い、それぞれのテーブルに分離させます。すると、以下のように3つのテーブルに分離しました。さらに、それぞれのテーブルに<ID>を付与していきます。
この<ID>はそれぞれ主キーとします。
主キーは分かりやすいように下線を付けておきます。
顧客マスタ
顧客マスタには<顧客ID>を付与します。
| 顧客ID | 顧客名 | 住所 | 連絡先 |
|---|---|---|---|
| CS0001 | 山田 | xxx | xxx |
| CS0001 | 山田 | xxx | xxx |
| CS0002 | 佐藤 | xxx | xxx |
| CS0003 | 武田 | xxx | xxx |
ここで<顧客ID CS0001>番の山田さんに注目してみましょう。同じ情報が重複しています。こういう場合は、重複を排除したテーブルの形にしましょう!
すると、顧客テーブルは下記のようになります。
| 顧客ID | 顧客名 | 住所 | 連絡先 |
|---|---|---|---|
| CS0001 | 山田 | xxx | xxx |
| CS0002 | 佐藤 | xxx | xxx |
| CS0003 | 武田 | xxx | xxx |
商品テーブル
商品テーブルには<商品ID>を付与します。
| 商品ID | 商品名 | 単価 | 区分コード | 区分名 |
|---|---|---|---|---|
| ITEM001 | コケ | ¥500 | S1 | 水生植物 |
| ITEM002 | スミレ | ¥1,000 | T1 | 多年草 |
| ITEM003 | 苗木 | ¥1,500 | J1 | 樹木類 |
| ITEM004 | タンポポ | ¥800 | T1 | 多年草 |
注文テーブル(未完成)
注文テーブルには<注文ID>を付与します。
| 注文ID | 注文日 | 顧客名 | 商品名 | 個数 |
|---|---|---|---|---|
| 00001 | 2015/10/01 | 山田 | コケ | 1 |
| 00001 | 2015/10/01 | 山田 | スミレ | 1 |
| 00002 | 2015/10/25 | 佐藤 | 苗木 | 1 |
| 00003 | 2015/11/14 | 武田 | タンポポ | 2 |
しかし、注文テーブルは、これでまだ完成ではありません。
<顧客テーブル><商品テーブル>でそれぞれ<顧客ID>、<商品ID>を付与しましたね?
注文テーブルの<顧客名><商品名>を<顧客ID><商品ID>に置き換えます。
すると、下記のようになります。
| 注文ID | 注文日 | 顧客ID | 商品ID | 個数 |
|---|---|---|---|---|
| 00001 | 2015/10/01 | CS0001 | ITEM001 | 1 |
| 00001 | 2015/10/01 | CS0001 | ITEM002 | 1 |
| 00002 | 2015/10/25 | CS0002 | ITEM003 | 1 |
| 00003 | 2015/11/14 | CS0004 | ITEM003 | 2 |
ここまで出来ましたか?しかし、まだ完成ではありません。
何故なのか?
<顧客ID CS0001>の山田さんは今回、商品<コケ>と<スミレ>を買いました。なので、レコードが二つ並んでいる状態です。もし、一人の人が100個の商品を買ったらどうなるでしょうか?レコードが縦に100個並ぶことになります。
非常に見にくいですよね?
なので、<注文テーブル>をさらに、<注文詳細テーブル>に分離させます。すると、以下のようになります。
注文テーブル(分離後)
| 注文ID | 注文日 | 顧客ID |
|---|---|---|
| 00001 | 2015/10/01 | CS0001 |
| 00001 | 2015/10/01 | CS0001 |
| 00002 | 2015/10/25 | CS0002 |
| 00003 | 2015/11/14 | CS0003 |
少し分かりにくいかもしれませネ・・・。注文テーブルは<いつ><誰が>の情報が分かれば、それでOKなのです。<誰が><何を><いくつ>買ったのかは注文詳細テーブルで管理したほうが見やすいというワケです。でも、そのまえに・・・!
<注文ID 00001>が重複していますね?
これを排除しましょう!
注文テーブル(重複排除後)
| 注文ID | 注文日 | 顧客ID |
|---|---|---|
| 00001 | 2015/10/01 | CS0001 |
| 00002 | 2015/10/25 | CS0002 |
| 00003 | 2015/11/14 | CS0003 |
これで、一人の人が100個の異なる商品を購入したとしても、注文テーブルのレコードは常に1つだけになります。
非常にスッキリしていて見やすいテーブルとなりました。
注文詳細テーブル(分離後)
| 顧客ID | 商品ID | 個数 |
|---|---|---|
| CS0001 | ITEM001 | 1 |
| CS0001 | ITEM002 | 1 |
| CS0002 | ITEM003 | 1 |
| CS0003 | ITEM004 | 2 |
この注文詳細テーブルは、異なる複数の商品を買えば、それだけレコードが下に追加されていきます。顧客IDが重複していますが、このテーブルの主キーは<顧客ID>と<商品ID>になります。この状態を<複合キー>といいます。つまり、二つで一つと見なすワケです。
さて、ここまで順調に出来たでしょうか?
ここまでで4つのテーブルが出来上がりました。もう一度第二正規化後の完成されたテーブルを確認してみましょう!
第二正規化完成後のテーブル
注文テーブル(完成形)
| 注文ID | 注文日 | 顧客ID |
|---|---|---|
| 00001 | 2015/10/01 | CS0001 |
| 00002 | 2015/10/25 | CS0002 |
| 00003 | 2015/11/14 | CS0003 |
注文詳細テーブル(完成形)
| 顧客ID | 商品ID | 個数 |
|---|---|---|
| CS0001 | ITEM001 | 1 |
| CS0001 | ITEM002 | 1 |
| CS0002 | ITEM003 | 1 |
| CS0003 | ITEM004 | 2 |
顧客マスタ(完成形)
| 顧客ID | 顧客名 | 住所 | 連絡先 |
|---|---|---|---|
| CS0001 | 山田 | xxx | xxx |
| CS0002 | 佐藤 | xxx | xxx |
| CS0003 | 武田 | xxx | xxx |
商品テーブル(完成形)
商品テーブルには<商品ID>を付与します。
| 商品ID | 商品名 | 単価 | 区分コード | 区分名 |
|---|---|---|---|---|
| ITEM001 | コケ | ¥500 | S1 | 水生植物 |
| ITEM002 | スミレ | ¥1,000 | T1 | 多年草 |
| ITEM003 | 苗木 | ¥1,500 | J1 | 樹木類 |
| ITEM004 | タンポポ | ¥800 | T1 | 多年草 |
ここまで出来ましたか?
さて、ここまでできたら第三正規化に進みましょう!
第三正規化
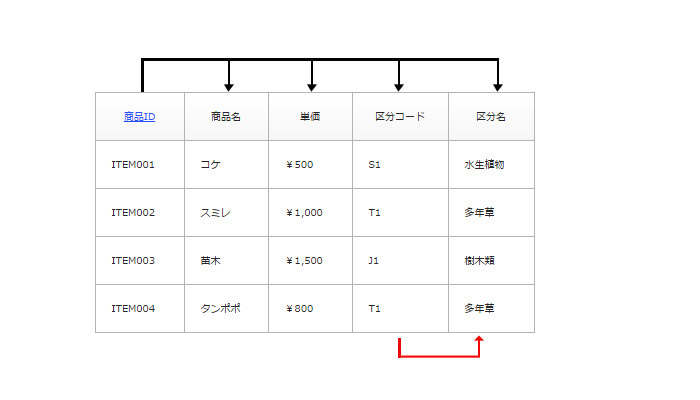
第三正規化は<推移従属関数>を分離することです。何のこっちゃ?と思いますが、キーワードは商品テーブルにあります。
- <区分コード><区分名>に着目してください。
- <区分コード>は<商品ID>に従属している。
- <区分名>は<区分コード>に従属している。
つまり、<商品ID> → <区分コード> → <区分名>が成り立ちます。この状態を<推移従属関数>と言います。
第三正規形ではこの<推移従属関数>を分離させます。
こちらが分離ごのテーブルです。
商品テーブル
| 商品ID | 商品名 | 単価 | 区分コード |
|---|---|---|---|
| ITEM001 | コケ | ¥500 | S1 |
| ITEM002 | スミレ | ¥1,000 | T1 |
| ITEM003 | 苗木 | ¥1,500 | J1 |
| ITEM004 | タンポポ | ¥800 | T1 |
商品区分マスタ
商品テーブルから<区分名>を分離させました。
| 区分コード | 区分名 |
|---|---|
| S1 | 水生植物 |
| T1 | 多年草 |
| J1 | 樹木類 |
| T1 | 多年草 |
これで第三正規化は完了です。第三正規化は少し難しかったかもしれません。仮に<区分コード><区分名>が無ければ、第二正規形でストップということになります。なので、必ず第三正規形まで行わなければいけないということではありません。
あくまでもケースバイケースなのです。
データベースのタブー
データベースでやってはいけないアンチパターンのことをバッドノウハウと呼びます。しかし、世の中にはアンチパターンによる設計が数多く存在していることも事実です。世の中には、「なんだ・・・これわ・・・」と思うような論理設計が意外に沢山あります。
こうした設計が生まれる理由は、「特に何も考えずに設計してしまった」ことによる場合が多いように思います。一度、データベースを構築し、運用しはじめたら、基本的に後戻りはできません。運用する前に、正しい論理設計かどうかを一度見直してみましょう。
論理設計(データベース設計)を行う際には、特に以下のことに気を付ける必要があります。
非スカラ値の原則
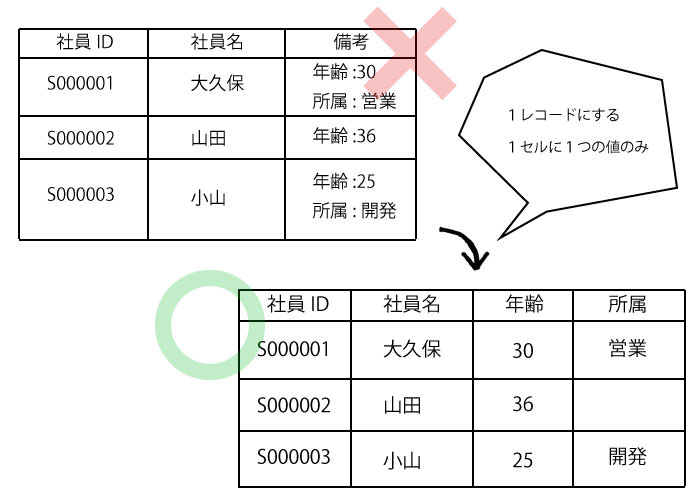
1セルの中に、複数の値が混在している状態です。
これは第一正規形未満の状態であり、この形でのデータベースの運用はダメです。空ならず、「1レコードにし、1セルには一つの値を格納する」が原則です。
ダブルミーニング
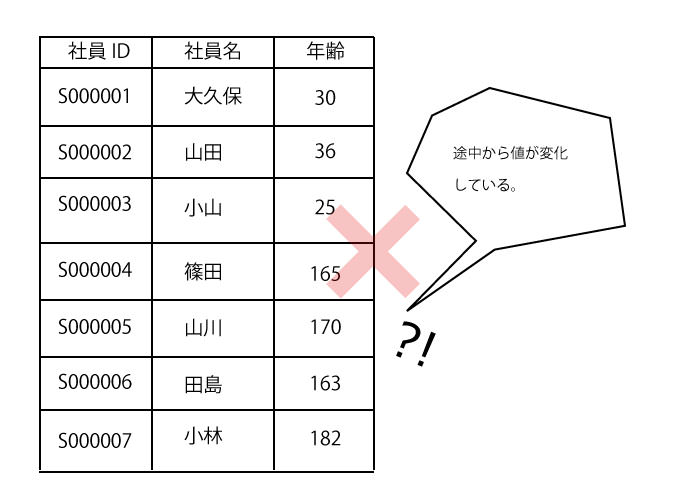
年齢のフィールドが途中から身長の値に変化しています。始めにフィールドの属性を決めたら、途中で別の値を挿入してはいけません。こういう場合は、年齢フィールドとは別に「身長フィールド」を別途作成する必要があります。
単一参照テーブル
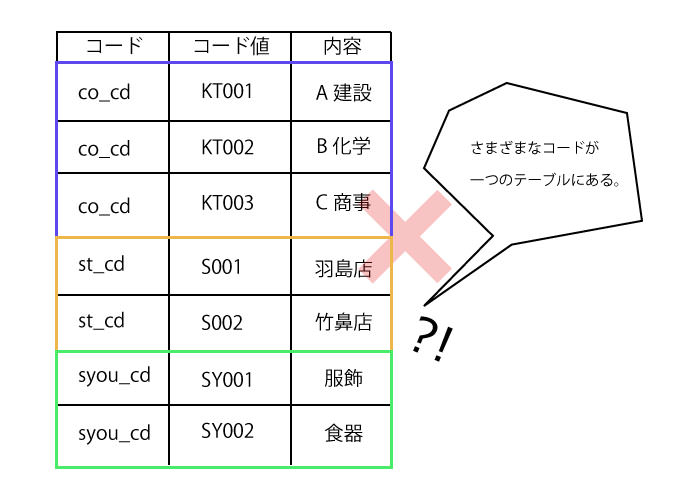
一つのテーブルの中に、いろんなコードが混在している状態です。上記のようなテーブルでも運用は可能です。しかし、これは好ましくありません。何がどこにあるのか分かりにくく、データの更新の際にも間違いが起こる可能性があります。
きちんとそれぞれのテーブルを作成しましょう!
テーブルの分割
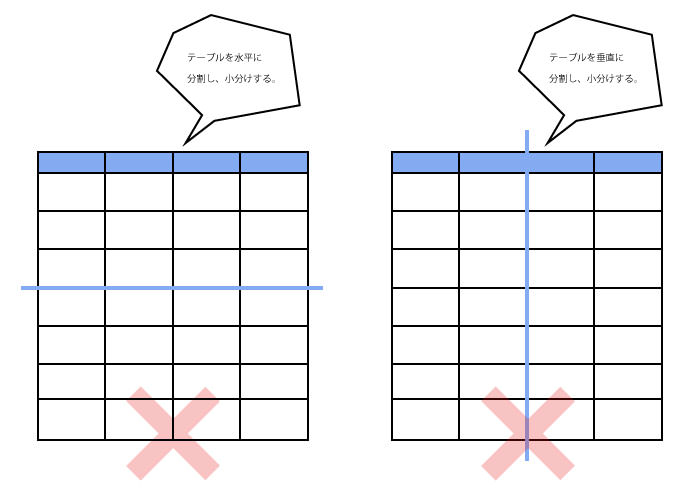
テーブルを水平・垂直に分割し、それぞれのデータを小分けするのは好ましくありません。テーブルを分割すると、データ量は見た目には減らすことができます。何十万件あるデータのアクセスのパフォーマンスも改善するかもしれません。しかし、これを繰り返すと、小分けした分だけテーブルが増えることになります。
データが増えれば増えるほど、より煩雑になり、拡張性にも欠けることになるでしょう。