皆さん、こんにちわ!
最新はいくつもの仕事が重なり、サイトの更新もままならない日々が続いています。複数の依頼を同時にこなすのは非常に難しいですね。
仕事の納期が最も短いものが最優先ですが、スケジュールを管理していないと、ぐちゃぐちゃの状態になってしまいます。WordPressなどで、スケジュール管理ができるプラグインは複数ありますが、まだまだ使いこなしていないように思います。なので結局は、タブレットで管理することが多くなってしまいました。
さて、今回はVBAの仕事で『テキスト処理』を使用する機会があったので、備忘録として残しておきたいと思います。
VBA CSV読み込み の困った問題
CSV形式のファイルを取り込んで、Excelの各セルに挿入したり、事前にクレンジングしたい場合があります。通常、CSV形式のファイルは、テキストファイルと同様の扱いとなっており、VBA(マクロ)からプログラムで中身のデータを取り込むことが可能です。
CSV形式のデータは『カンマ』によって区切られており、プログラムでセパレート(分割)して処理を行います。
例えば下記のような感じです。
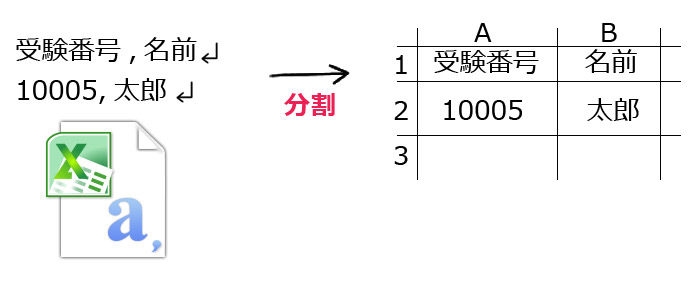
ですが・・・、文字列の中に不要なカンマが存在していると、思うような結果になりません。
例えば以下のようなケースです。
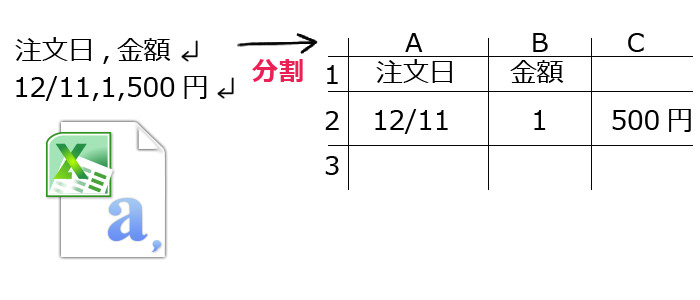
上記のケースでも分かるように、『文字列の中にカンマ』がある場合、おかしな位置で区切られてしまい結果がズレてしまいます。これでは、データの整合性が保てません。今回のVBAのコードでは、この文字列の中の不要なカンマを取り除き、正常に区切られるようなプログラムを作成します。
今回のプラグラムの処理イメージ

CSV形式のデータファイルをVBAのOpenステートメントを利用して取り込み、不要なカンマを置換します。抜き出したデータをExcel形式のファイル(CSVでも可)の対象のセルに、各データを格納します。
なるべく処理を短縮できるように、QueryTablesを使用します。
処理の順序

処理を作成するにあたって、処理の順序を考えてみました。
この方法は、CSV形式のデータがダブルコーテーションで囲まれていることが前提になっています!
OpenステートメントのInputで一行ずつ取り込みます。次に、文字列を一つずつ調べ、ダブルコーテーションの数を数えます。これは、偶数の次に存在するカンマは『区切りのカンマ』、奇数の次に存在するものは『不要なカンマ』と判定させるためです。不要なカンマを発見したら、空文字(もしくは他の記号でも可)に置換します。最後に、文字列を連結させ、元に戻すという処理を入れます。
いろいろ方法はあるでしょうが、私が考えた処理は以上のような感じです。
これを元に、プログラムを作成していきましょう。
CSV形式のデータを読み込む時のカンマ処理
ここでは、CSV形式のファイルを読み込み、文字列の中に不要なカンマがあれば削除するという処理を行っています。他にも不要なカンマを削除する方法はいくつかあると思いますが、私はこの方法で行いました。
Sub CsvReading()
Dim tmp As Variant, tmp2 As Variant '分割されたデータを格納
Dim i As Long, cnt As Long 'ループ用カウント格納変数
Dim buf As String 'テキスト形式のラインを格納
Dim strtmp As String '抜出した文字列格納
Dim tmpArray() As String '配列 1列分のデータ格納
Dim dcCount As Long 'ダブルコーテーションのカウント
Dim conectBuf As String '文字列連結格納
'エラー処理
On Error GoTo myError
'ダブルコーテーションカウント数 初期化
dcCount = 0
'連結文字列 初期化
conectBuf = ""
'テキスト処理
Open "CSVファイル名" For Input As #1
'初期化
cnt = 0
'最終行まで処理
Do Until EOF(1)
'bufに1行分のデータ読み込み
Line Input #1, buf
'インクリメント
cnt = cnt + 1
'分割する前に、文字列の中にあるカンマを特定し、置き換える
'一文字づつ判定し、数字かどうかを判定
'ダブルコーテーションを調べ、奇数の次にカンマがあるか?を判定
ReDim tmpArray(1 To Len(buf))
For i = 1 To UBound(tmpArray)
'1文字づつ抜出す
strtmp = Mid(buf, i, 1)
'ダブルコーテーションが奇数か?偶数か?を判別
If strtmp = """" Then
test = "発見"
'発見した場合、カウント
dcCount = dcCount + 1
End If
'ダブルコーテーション カウント比較
comp = dcCount Mod 2
'ダブルコーテーションが奇数であり、かつ文字列の中にカンマが存在する場合、カンマを排除
If comp <> 0 And strtmp = "," Then
strtmp = Replace(strtmp, ",", "")
End If
'文字列連結
conectBuf = conectBuf & strtmp
'デバック用
'Debug.Print conectBuf
Next i
'カンマで分割
tmp = Split(conectBuf, ",")
'1行分の処理
For i = 0 To UBound(tmp)
'前後の不要な空白を削除
strtmp = Trim(Replace(tmp(i), vbLf, ""))
'ダブルコーテーションを削除
strtmp = Replace(strtmp, """", "")
'全角空白を削除
strtmp = Replace(strtmp, " ", "")
'セルに書き込み
Workbooks("CSVファイル名").Worksheets("シート名").Cells(cnt, i + 1).Value = strtmp
Next i
'初期化
conectBuf = ""
Loop
Close #1
'保存
Workbooks("CSVファイル名").SaveAs filename:="保存後のファイル名", Local:=True
'閉じる
Workbooks("ファイル名").Close
Open ステートメント
27行目 Open ファイル名 for Input as #ファイル番号
- ファイル名 → 対象のファイル名を記述する。パス指定も可(C:\sample.csv)
- Input → 入力モードで開く(他にもいろいろモードがある)
- #ファイル番号 → 1~511の範囲で任意のファイル番号を指定する
- (※1~255を割り当てると、他のアプリケーションからはアクセス出来なくなる)
- (※256~511を割り当てると、他のアプリケーションからアクセス出来るようになる)
EOF関数
33行目 Do Until EOF(1)
EOFは、テキストファイルの読み取りポイントが終端になると、Trueを返します。
つまり、Falseの間だけ読み込みを繰り返すします。
Line Input ステートメント
36行目 Line Input #番号 , 変数
Line Inputステートメントは、1行分のデータを読み込み、読み込みポイントを次の行に移動させます。EOF関数と組み合わせることで、テキストファイルの終端になるまで、繰り返しデータを取得できます。
- #番号 → Openステートメントで記述したファイル番号
- 変数 → 読み込んだ行を格納する(String型の)変数
変数には下記のように読み込んだ1行分のデータが格納されます。
Line Input #1 , buf
buf = “2015/12/12” , “テスト太郎” , “301-3335” , “岐阜県高山市大木3-1” , “050-3333-2222”
ReDim ステートメント
44行目 ReDim 配列名(1 To Len(buf))
動的配列の要素数や次元数を変更します。通常、配列は要素数を決めてデータを格納しますが、可変データには対応できません。そこで、データの長さをLen関数で取得し、RiDimステートメントで設定しています。
Mod オペレータ
62行目 数値 Mod 数値
Modは2つの数字を除算して剰余のみを返します。例えば『14 Mod 4』の余りは『2』となります。コードでは dcCount Mod 2 となっていますが、dcCountには数値型(Integer)の数値が格納されています。
Modを使用することによって、2で割り切れるのであれば『偶数』、割り切れないのであれば『奇数』と判定しています。これによってダブルコーテーションをカウントし、奇数番目の次に存在する不要なカンマを判定しています。
Replace関数
68行目 Replace(文字列 , “,” , “”)
指定された文字列の一部を、指定された文字列に置換します。Replaceで、文字列の中に存在する不要なカンマを排除しています。
例えば以下のような感じになります。
①文字列 = ”2015/12/12″ , “テスト太郎” , “150,550円”
↓
②文字列 = ”2015/12/12″ , “テスト太郎” , “150550円”
上記の例では、①の”150,550円”の文字列の中に桁区切りのカンマが存在しています。このままでは、カンマで区切られてしまうため、思うような結果が得られません。Replaceでカンマを置き換えると、②のようにカンマを排除することができます。
Replace関数使い方を参照
Split関数
83行目 tmp = Split(文字列 , “,”)
Split関数は各要素ごとに区切られた文字列を、指定した区切り文字で分割し、一次元配列として返します。83行目の例では、カンマで区切り、tmpというバリアント型変数に格納しています。Split関数の返り値は配列のため、受け取る側の変数は『バリアント型』 or 『動的配列』になります。
例えば以下のような感じになります。
tmp = Split(”2015/12/12 , テスト太郎 , 岐阜” , “,”)
↓
- tmp(0)・・・2015/12/12
- tmp(1)・・・テスト太郎
- tmp(2)・・・岐阜
ブックの追加とデータの移行
不要なカンマを処理したら、そのデータを別のExcel形式のファイルへデータを書き込みます。
ここでは、件数が多くなることを想定し、QueryTablesを使用しています。QueryTablesは件数が多ければ多いほど効果を発揮しますが、少ない件数ではあまり恩恵は得られません。よってケース by ケースで使用してください。
'新規ブック追加
Workbooks.Add
'ブックを保存
Workbooks(ActiveWorkbook.Name).SaveAs filename:=gXlsxFilePath
'QueryTables/Connectionで設定するファイルパス
strPath = "TEXT;" & gStrOpenFileName
'QueryTables.Add(Connection(必須・バリアント型), Destination(必須・Range))
With Workbooks(ActiveWorkbook.Name).Worksheets(1).QueryTables.Add(Connection:=strPath, Destination:=Worksheets(1).Range("A1"))
.Name = "link1"
.TextFileCommaDelimiter = True 'カンマ区切り
.TextFilePlatform = xlWindows 'コード
.Refresh
End With
'リンク切断
ActiveWorkbook.Names("link1").Delete
'シート名のリネーム
ActiveSheet.Name = gDataSheet
'ブックを保存
Workbooks(ActiveWorkbook.Name).SaveAs filename:=gXlsxFilePath, Local:=True
Exit Sub
myError:
MsgBox "テキスト処理エラー" & vbCrLf & "システム管理者にお問い合わせください" & vbCrLf & "エラー内容:" & Err.Description, vbExclamation
End
End Sub
QueryTables.Add メソッド
14行目 With WordBook.WorkSheet.QueryTables.Add(Connection=パス, Destination=基準セル)
QueryTables.Addを使用する際には、必ずWordBook名、WorkSheets名(or 番号)を記述しなければいけません。もしくは、Setを使用し、あらかじめ変数に格納しておく方法もあります。
また、QueryTables.Addには使用できるプロパティが数多くあります。プロパティの使い方と設定方法は、MSDNを参照してください。
- Connection・・・ドライブ名を含む、対象ファイルまでのフルパスを指定する
- Destination・・・基準となるセルの位置を指定します。(例:Cells(1,1) or Range(”A1″))
QueryTables.Addメソッドの Name プロパティ
15行目 Name = 文字列
オブジェクトの名前を表す文字列型の値を設定(or 取得)します。この文字列は任意のものでOKです。例えば、Name = “20151212Test”でも可能です。
QueryTables.Addメソッドの TextFileCommaDelimiter プロパティ
16行目 TextFileCommaDelimiter = Ture
カンマ区切りで分割する場合は、TextFileCommaDelimiterプロパティをTureに設定します。
TextFileCommaDelimiterプロパティ使い方を参照
QueryTables.Addメソッドの TextFilePlatform プロパティ
17行目 TextFilePlatform = xlWindows
インポートするファイルのプラットフォームを指定します。上記の例では、プラットフォームは『Windows』で使用する、という定数を設定しています。このプロパティはデータインポートの時に使用されるコードを決定するためのものです。
TextFilePlatform で使用できる定数は以下の通り。
- xlMacintosh
- xlMSDOS
- xlWindows
この項目は無くてもいいかもしれません。MSDNの説明を参照すると、『規定値はテキストファイルウィザードで現在[元のファイル]に設定されている値』となっています。
とりあえず、ここまでのプログラムで『CSVデータ取り込み → 不要なカンマ削除 → 新規Excelブックに書き出し』までの処理は終了です。もっと考慮すれば、さらに高速な手法があると思います。Inputではなく、Binaryを使うとか・・・。
また、その時にはいろいろな問題が発生するかもしれませんね。
今回のようにVBAでテキスト処理をするためには、極力高速化したほうが良いでしょう。件数が数千件~数万になれば、それだけ処理に時間がかかりイライラすることになります。とはいえ、まずは自分が考えた処理が正常に動作することが先決ですけどね。
高速化の問題はまた改めて考えてみたいと思います。
取り急ぎ、今回はここまで。